C#数组
数组是允许将多个数据项作为集合来处理的机制。CLR支持一维、多维和交错数组(即数组构成的数组)。
所有数组类型都隐式地从 System.Array 抽象类派生,后者又派生自 System.Object ,这意味着数组始终是引用类型,是在托管堆上分配的。
Int32[] myIntegers; // 声明一个数组引用,myIntegers刚开始为null
myIntegers = new Int32[100]; // 创建含有100个Int32的数组,所有Int32都被初始化为0
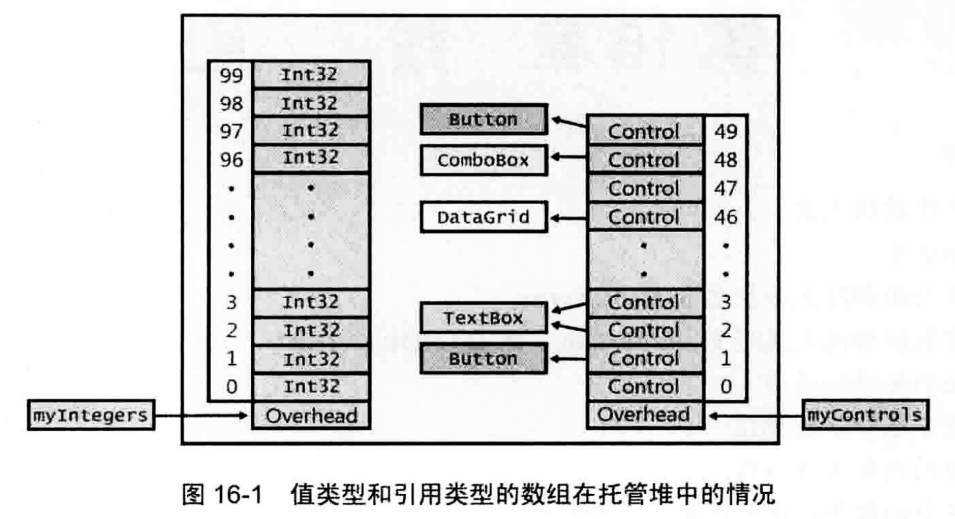
由于数组是引用类型,所以会在托管堆上分配容纳100个未装箱Int32所需的内存块。除了数组元素,数组对象占据的内存块还包含了一个类型对象的指针、一个同步块索引和一些额外的成员。
// 还可以创建引用类型的数组
Control[] myControls; // 声明一个数组引用,myControls刚开始为null
myControls = new Controls[50]; // 创建含有50个Controls引用的数组,这些引用全被初始化为null
// 创建实际的对象
myControls[1] = new Button();
myControls[2] = new TextBox();
myControls[3] = myControls[2];
myControls[46] = new DataGrid();
myControls[48] = new ComboBox();
myControls[49] = new Button();
当前托管堆中的情况如下图:
每个数组都关联了一些额外的开销信息,包括数组的秩(或称数组的维数)、数组每一维的下限和每一维的长度,还包括数组的元素类型。
为了符合“公共语言规范”(Common Language Specification, CLS)的要求,所有数组都必须是0基数组(即最小索引为0)。(PS:CLR支持非0基数组)
应尽可能使用一维0基数组(或称SZ数组或向量),它的性能是最佳的,因为可以使用一些特殊的IL指令(比如 newarr,ldelem,ldelema,ldlen和stelem)来处理。
CLR会验证数组索引的有效性,若无效会导致
System.IndexOutOfRangeException异常。通常,索引范围检查对性能的影响微乎其微,因为JIT编译器通常只在循坏开始之前检查一次数组边界,而不是每次循环迭代都检查。如:
for (Int32 i = 0; i < a.Length; i++)JIT编译器知道for循环要访问0到 Length - 1 的数组元素,所以JIT编译器会生成代码来检查是否
(0 >= a.GetLowerBound(0) && (Length - 1) <= a.GetUpperBound(0)),这个检查是在循环之前发生。遗憾的是,对于“非0基一维数组”或“多维数组”,JIT编译器不会将索引检查从循环中拿出来,所以每次数组访问都要验证指定的索引。所以如果很关心性能,考虑用由数组构成的数组(即交错数组)代替矩形数组。
初始化数组元素
C# 允许用一个语句同时创建数组对象和初始化:
String[] names = new String[] { "Aidan", "Grant" };
大括号中的以逗号分隔的数据项成为数组初始化器(array initializer)。
还有一些别的方式:
// 利用C#的隐式类型的局部变量功能
var names = new String[] { "Aidan", "Grant" };
// 利用C#的隐式类型的局部变量功能和隐式类型的数组功能
var names = new String[] { "Aidan", "Grant", null }; // null 可隐式转型为任意引用类型(包括String)
// 作为初始化数组时的一个额外的语法奖励
String[] names = { "Aidan", "Grant" };
// 试图使用隐式类型的局部变量功能(错误)
var names = { "Aidan", "Grant" };
// 使用C#的隐式类型的局部变量、隐式类型的数组和匿名类型功能
var kids = new [] {new { Name = "Aidan" }, new { Name = "Grant" }};
// 示例用法
foreach (var kid in kids)
Console.WriteLine(kid.Name);
数组转型
对于元素为引用类型的数组,CLR允许将数组元素从一种类型转型另一种。成功转型要求数组维数相同,而且必须存在从元素源类型到目标类型的隐式或显示转换。
CLR不允许将值类型元素的数组转型为其他任何类型(不过可用 Array.Copy 方法创建新数组并在其中填充元素来模拟这种效果)。
注意,
Array.Copy方法执行的是浅拷贝。
Array.Copy 的作用不仅仅是将元素从一个数组复制到另一个,还能在复制每个数组元素时进行必要的类型转换,具体如下:
- 将值类型的元素装箱为引用类型的元素,比如将一个
Int32[]复制到一个Object[]中; - 将引用类型的元素拆箱为值类型的元素,比如将一个
Object[]复制到一个Int32[]中; - 加宽CLR基元值类型,比如将一个
Int32[]的元素复制到一个Double[]中; - 在两个数组之间复制时,如果仅从数组类型证明不了两者的兼容性,比如从
Object[]转型为IFormattable[],就根据需要对元素进行向下类型转换。如果Object[]中的每个对象都实现了IFormattable,Array.Copy方法就能成功执行
有时确实需要将数组从一种类型转换为另一种类型,这种功能称为数组协变性(array covariance),要清楚由此二来的性能损失。如下代码:
String[] sa = new String[100];
Object[] oa = sa; // oa引用一个String数组
oa[5] = "Jeff"; // 性能损失:CLR检查oa的元素类型是不是String;检查通过
oa[3] = 5; // 性能损失:CLR检查oa的元素类型是不是Int32;发现有错,抛出ArrayTypeMismatchException异常
注:
- 如果只是需要将数组的某些元素复制到另一个数组,可选择
System.Buffer的BlockCopy方法,它比Array.Copy方法快。- 但
BlockCopy方法只支持基元类型,不提供转型能力;- 设计
BlockCopy的目的实际是将按位兼容的数组从一个数组类型复制到另一个按位兼容的数组类型;- 要将一个数组的元素可靠地复制到另一个数组,应该使用
System.Array的ConstrainedCopy方法- 该方法要么完成复制,要么抛出异常,总之不会破坏目标数组中的数据;
ConstrainedCopy要求源数组的元素类型要么与目标数组的元素类型相同,要么派生自目标数组的元素类型;- 它不执行任何装箱、拆箱或向下类型转换;
所有数组都隐式派生自 System.Array
像下面这样声明数组变量:
FileStream[] fsArray;
CLR会自动会 AppDomain 创建一个 FileStream[] 类型,该类型隐式派生自 System.Array 类型。
所有数组都隐式实现 IEnumerable,ICollection 和 IList
许多方法都能操纵各种各样的集合对象,因为它们声明为允许获取 IEnumerable,ICollection 和 IList 等参数。
CLR团队不希望 System.Array 实现 IEnumerable<T>,ICollection<T> 和 IList<T> 。若在 System.Array 上定义这些接口,就会为所有数组类型启用这些接口,所以CLR耍了一个小花招:创建一维0基数组类型时,CLR自动使数组类型实现 IEnumerable<T>,ICollection<T> 和 IList<T> (T是数组元素的类型)。同时,还为数组类型的所有基类型实现这三个接口,只要它们是引用类型。如下:
Object
Array (非泛型 IEnumerable, ICollection, IList)
Object[] (IEnumerable, ICollection, IList of Object)
String[] (IEnumerable, ICollection, IList of String)
Stream[] (IEnumerable, ICollection, IList of Stream)
FileStream[] (IEnumerable, ICollection, IList of FileStream)
注:如果数组包含值类型的元素,数组类型不会为元素的基类型实现接口。
数组的传递和返回
数组作为实参传给方法时,实际传递的是对该数组的引用。因此,被调用的方法能修改数组中的元素。
如果定义返回数组引用的方法,而且数组中不包含元素,那么可以:
- 返回null
- 返回对包含零个元素的一个数组的引用(推荐)
创建下限非零的数组
能创建和操作下限非0的数组(但性能较差),可以调用数组的静态 CreateInstance 方法来动态创建自己的数组。该方法有若干个重载版本,允许指定数组元素的类型、数组的维数、每一维的下限和每一维的元素书数目。
CreateInstance为数组分配内存,将参数信息保存到数组的内存块的开销(overhead)部分,然后返回对该数组的引用;- 如果数组维数是2或2以上,就可以把
CreateInstance返回的引用转型为一个ElementType[]变量(ElementType[]要替换为类型名称),以简化对数组中的元素的访问; - 如果只有一维,C#要求必须使用该 Array 的
GetValue和SetValue方法访问数组元素;
演示代码如下:
public sealed class DynamicArrays
{
public static void Main()
{
Int32[] lowerBounds = { 2005, 1 };
Int32[] lengths = { 5, 4 };
Decimal[,] quarterlyRevenue = (Decimal[,]) Array.CreateInstance(typeof(Decimal), lengths, lowerBounds);
Int32 firstYear = quarterlyRevenue.GetLowerBound(0);
Int32 lastYear = quarterlyRevenue.GetUpperBound(0);
Int32 firstQuarter = quarterlyRevenue.GetLowerBound(1);
Int32 lastQuarter = quarterlyRevenue.GetUpperBound(1);
for (Int32 year = firstYear; year <= lastYear; year++)
{
Console.Write(year + " ");
for (Int32 quarter = firstQuarter; quarter <= lastQuarter; quarter++)
{
Console.Write("{0, 9:C}", quarterlyRevenue[year, quarter]);
}
Console.WriteLine();
}
}
}
// 输出:
2005 $0.00 $0.00 $0.00 $0.00
2006 $0.00 $0.00 $0.00 $0.00
2007 $0.00 $0.00 $0.00 $0.00
2008 $0.00 $0.00 $0.00 $0.00
2009 $0.00 $0.00 $0.00 $0.00
数组的内部工作原理
CLR内部实际支持两种不同的数组
- 下限为0的一维数组(一维0基数组)
- 下限未知的一维或多维数组
不同种类的数组:
public sealed class Program
{
public static void Main()
{
Array a;
// 创建一维的0基数组,不包含任何元素
a = new String[0];
Console.WriteLine(a.GetType()); // System.String[]
// 创建一维的0基数组,不包含任何元素
a = Array.CreateInstance(typeof(String), new Int32[] { 0 }, new Int32[] { 0 });
Console.WriteLine(a.GetType()); // System.String[]
// 创建一维的1基数组,不包含任何元素
a = Array.CreateInstance(typeof(String), new Int32[] { 0 }, new Int32[] { 1 });
Console.WriteLine(a.GetType()); // System.String[*]
// 创建二维的0基数组,不包含任何元素
a = new String[0, 0];
Console.WriteLine(a.GetType()); // System.String[,],其实应该是System.String[*,*],但CLR觉得大量*会使开发人员混淆,所以不使用*符号
// 创建二维的0基数组,不包含任何元素
a = Array.CreateInstance(typeof(String), new Int32[] { 0, 0 }, new Int32[] { 0, 0 });
Console.WriteLine(a.GetType()); // System.String[,]
// 创建二维的1基数组,不包含任何元素
a = Array.CreateInstance(typeof(String), new Int32[] { 0, 0 }, new Int32[] { 1, 1 });
Console.WriteLine(a.GetType()); // System.String[,]
}
}
不安全的数组访问和固定大小的数组
不安全的数组访问非常强大,因为它允许访问以下元素:
- 堆上的托管数组对象中的元素
- 非托管堆上的数组中的元素
- 线程栈上的数组中的元素
在线程栈上分配数组,需要通过C#的 stackalloc 语句来完成(类似于C的 alloca 函数), stackalloc 语句只能创建一维0基、由值类型元素构成的数组,而且值类型绝对不能包含任何引用类型的字段。
实际上,应该把它的作用看成是分配一个内存块,这个内存块可以使用不安全的指针来操纵。
演示代码:
public static class Program
{
public static void Main()
{
StackallocDemo();
InlineArrayDemo();
}
private static void StackallocDemo()
{
unsafe
{
const Int32 width = 20;
Char* pc = stackalloc Char[width]; // 在栈上分配数组
String s = "Jeffrey Richter"; // 15个字符
for (Int32 index = 0; index < width; index++)
{
pc [width - index - 1] = (index < s.Length) ? s[index] : ".";
}
Console.WriteLine(new String(pc, 0, width)); // 输出 .....rethciR yerffeJ
}
}
private static void InlineArrayDemo()
{
unsafe
{
CharArray ca; // 在栈上分配数组
Int32 widthInBytes = sizeof(CharArray);
Int32 width = widthInBytes / 2;
String s = "Jeffrey Richter"; // 15个字符
for (Int32 index = 0; index < width; index++)
{
ca.Characters [width - index - 1] = (index < s.Length) ? s[index] : ".";
}
Console.WriteLine(new String(ca.Characters, 0, width)); // 输出 .....rethciR yerffeJ
}
}
}
internal unsafe struct CharArray
{
// 这个数组内联(嵌入)到结构中
public fixed Char Characters[20];
}
通常,用于数组是引用类型,所以结构中定义的数组字段实际只是指向数组的指针或引用;数组本身在结构的内存的外部。
不过也可以像上述代码中的 CharArray 结构那样,直接将数组嵌入结构。在结构中嵌入数组需满足以下几个条件:
- 类型必须是结构(值类型);不能在类(引用类型)中嵌入数组
- 字段或其定义结构必须用
unsafe关键字标记 - 数组字段必须用
fixed关键字标记 - 数组必须是一维0基数组
- 数组的元素类型必须是以下类型之一:Boolean, Char, Byte, SByte, Int16, Int32, UInt16, UInt32, Int64, UInt64, Single 或 Double